This tutorial builds on the previous one, Collaborative Judgements, and assumes you have already set up a book with query/document pairs ready for evaluation. In this guide, we will explore the Human Rating Interface, which is designed to streamline the process of assigning judgements to query/document pairs.
The role of a human rater is accessible to anyone with the right task description. No technical background is required—just the ability to assess how well a document matches the information need for a given query.
Overview of the Human Rating Interface
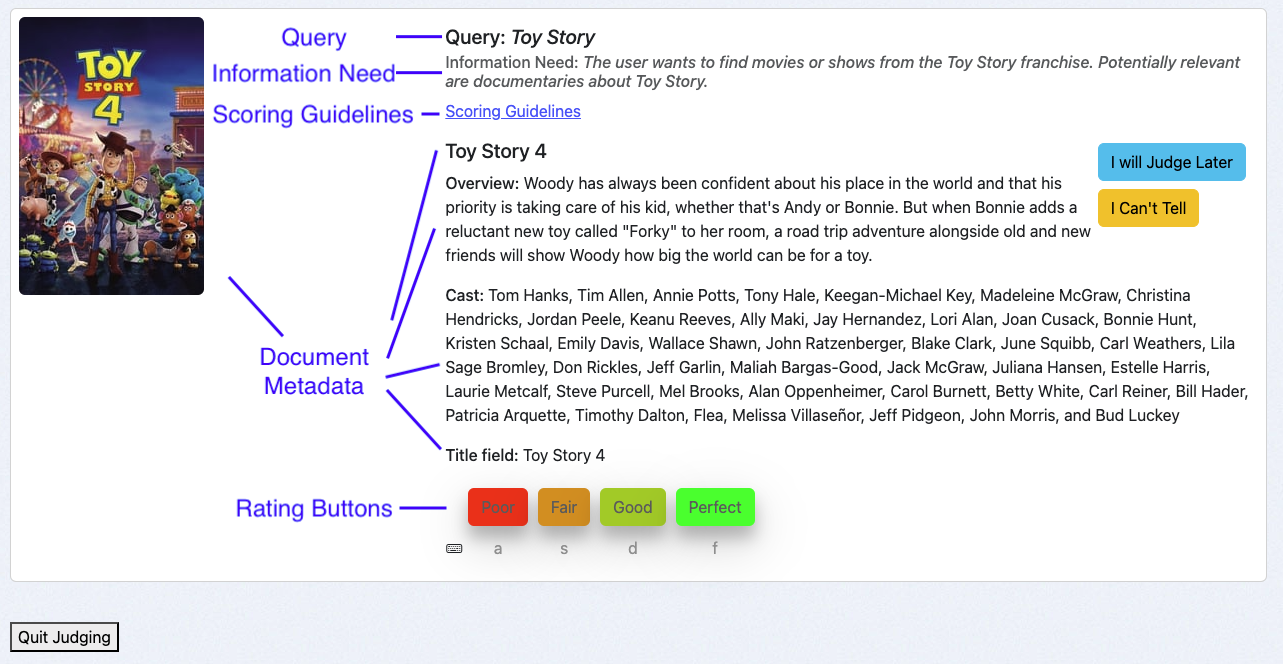
The Human Rating Interface is thoughtfully structured to assist raters in providing accurate and consistent judgements. The interface consists of the following key components:
- Query: Displays the query associated with the query/document pair being evaluated.
- Information Need: Highlights the specified user intent behind the query, guiding raters to make informed decisions.
- Scoring Guidelines: Provides clear instructions for raters on how to apply the available grades to the query/document pairs.
- Document Metadata: Shows relevant fields (for example title, cast, or an image) describing the document to be rated, which correspond to the return fields of the case.
- Rating Buttons: Allows raters to assign judgements using a set of buttons. Below each button, keyboard shortcuts are displayed to improve efficiency and speed.
Using the Human Rating Interface
As a human rater I access to the interface via the book overview:
- Navigate to the case interface and click Judgements.
- Click on More Judgements are Needed!.
The system will present a query/document pair that you haven’t rated yet and that requires additional judgements. This is determined by the Book’s selection strategy:
- Single Rater: A single judgement per query/doc pair.
- Multiple Raters: Up to three judgements per query/doc pair.
Best Practices for Judging
To maintain consistency and ensure high-quality judgements, follow these best practices:
1. Review Presented Information in a Consistent Order
Evaluate the following elements sequentially for each query/document pair:
- Query: Understand the user’s search intent.
- Information Need: Identify the intent and expectations specified for the query.
- Document Metadata: Assess the document’s relevance based on the provided fields.
2. Refer to Scoring Guidelines
Use the scoring guidelines and any additional instructions provided to maintain consistency across judgements.
3. Use the I Will Judge Later and I Can’t Tell Options
- If you’re unsure about a pair, use the I Will Judge Later button to skip and revisit it later.
- Select I Can’t Tell when you cannot judge a pair. This option allows you to provide an explanation, which can be invaluable to relevance engineers (e.g., to identify ambiguities or issues in the task description) and other team members.
4. Take Frequent Breaks
Judging can be mentally taxing. Regular breaks help maintain the quality of your work and reduce fatigue.
Examples
Two examples to illustrate a Perfect match and a Poor match
A "Perfect" Match
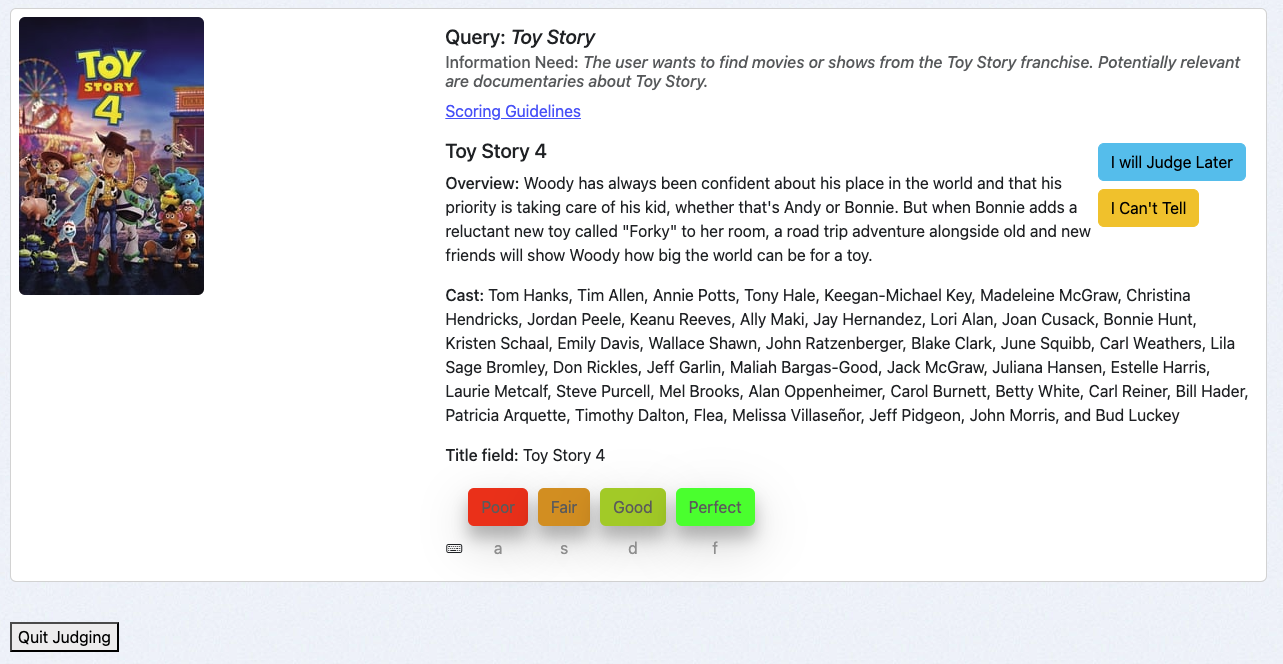
For the query Toy Story, the user intends to find movies from the Toy Story franchise. The document Toy Story 4 is a movie from this franchise, making it a Perfect match.
To save this judgement in the Book:
- Click the Perfect button or
- Use the keyboard shortcut
f.
A "Poor" Match
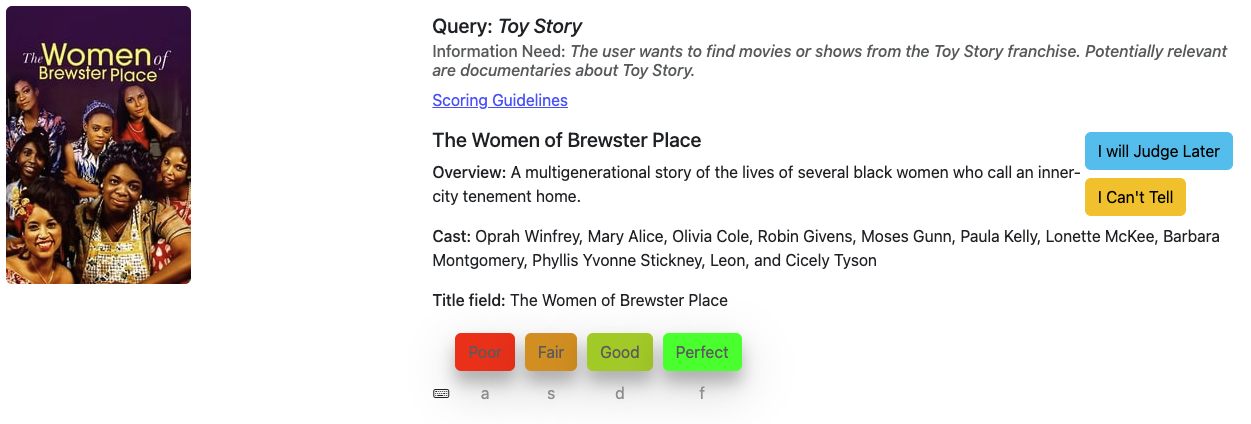
For the same query Toy Story, the document The Women of Brewster Place is unrelated to the Toy Story franchise, making it a Poor match.
To save this judgement in the Book:
- Click the Poor button or
- Use the keyboard shortcut
a.
Next Steps
Now that you’ve explored the Human Rating Interface, your next step is to continue completing judgements for all available query/document pairs in your Book. Each judgement you provide directly contributes to improving the search experience, helping users find the information they need more effectively.
If you need a refresher on how query/document pairs are set up or the foundational concepts behind this process, revisit the Collaborative Judgements tutorial. It provides valuable context and ensures you’re fully aligned with the objectives of this task.