How to Use Ollama as LLM
You can use Ollama hosted models instead of OpenAI as the LLM to power your AI Judges. This how to will walk you through the steps for configuring Quepid to talk to Ollama.
It assumes that you have deployed Quepid using Docker Compose and the docker-compose.yml that ships with Quepid. However, the general approach will work as well with any deployed Ollama server.
If you need to start the Ollama server then run docker compose up ollama. This starts an empty Ollama service.
Now let's download the smallest Qwen 2.5 model, which is just 398 MB, by running docker exec ollama ollama pull qwen2.5:0.5b.
Now you are ready to configure you AI Judge to use a local model.
Bring up your AI Judge editing screen:
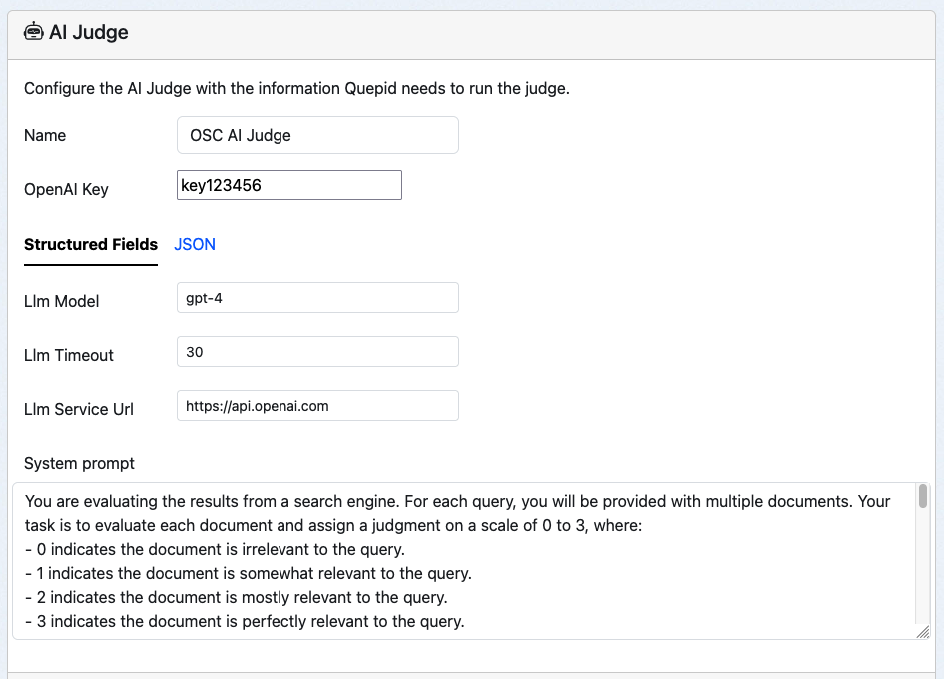
Make the following changes and save them. Local LLM models may run quite slowly, so having a long timeout may be needed.
| Key | Value |
|---|---|
| LLM Key | Not used by Ollama, but Quepid requires something. abc123 |
| Llm Service Url | http://ollama:11434 |
| Llm Model | qwen2.5:0.5b |
| Llm Timeout | 60 |
Don't forget to go to Book > Settings and add the newly created Judge to the book.
Then go to the Book > Judgement Stats page and try out the AI Judge!
Other models that you may want to play with are https://ollama.com/library/olmo2 and https://ollama.com/library/llama3.2:1b.
You may need to bump up the RAM allocated to Docker to use the larger models!
Some other useful commands are docker exec ollama ollama stop qwen2.5:0.5b to unload a model, docker exec ollama ollama rm qwen2.5:0.5b to remove a model.